Scholastica, a journal publishing technology solutions provider, has incorporated ROR IDs into its Peer Review System, Production Service, and Open Access Publishing Platform. In this interview with Cory Schires, Scholastica co-founder and CTO, we discuss the two phases of ROR implementation, the pros and cons of displaying ROR IDs, what makes sense about ROR’s level of granularity, and the importance of reliable APIs.
Key quotations
“I would say the benefit to the users is getting better metadata. It’s an obvious answer, but users don’t always know about metadata. They also might not think of metadata as a feature, but we do. At Scholastica, we care about taking steps to enrich metadata – like adding ROR IDs, for example, on behalf of our customers, so they don’t have to worry about the technical aspects of metadata collection or creation and can instead focus on maximizing the discovery benefits.”
“Before ROR, I was aware of some of the commercial competitors, but they were prohibitively expensive for many smaller journals and more difficult to integrate. We work with bigger journals and presses, but we also work with many small journals, and the price was a concern for our customers. When ROR came out as something that was free and community-supported, that was super important.”
“I would say one thing I like about how y’all have set up ROR is your approach to parent-child or nested institutions. Obviously, you can go super deep on that and get extremely detailed. And I think y’all have helpfully resisted the urge to go deeper than makes sense, in my opinion. I mean, people don’t always realize that: it’s kind of counterintuitive that there can be an inverse relationship between the richness of a dataset and its utility. It can get so granular, and that’s cool, but then it’s really hard to make any kind of inference from the data.”
– Cory Schires, Co-founder and Chief Technology Officer, Scholastica
Amanda French
Thanks for joining us! Please tell us your name, title, and organization.
Cory Schires
My name is Cory Schires. I am a co-founder and CTO at Scholastica.
Amanda French
Tell us about Scholastica.
Cory Schires
Scholastica was founded in 2012 by myself, Brian Cody, and Robert Walsh. We met at the University of Chicago. To this day, we all share a deep affection for academia. Scholastica now has more products, and we’ve expanded over the last ten years, but our core mission remains the same. We want to empower academic organizations of any size to publish top quality journals, more effectively, efficiently, and affordably. We’re also huge proponents of open access. Currently, all the journals published on Scholastica are open access.
Amanda French
That’s amazing. When and where did you personally first hear about ROR?
Cory Schires
I don’t remember exactly. It was probably in the context of Crossref. Actually, I also often find out about industry developments on Scholastica’s blog, run by our marketing director Danielle Padula. It’s a good resource. Like others in the industry, I’m busy trying to keep track of many different things, so I use our blog to stay abreast of new developments.
Amanda French
I was about to say! Danielle is so impressive. She actually just published an interview with me, so we have dueling interviews. She’s very organized and on top of things. I’m jealous.
Cory Schires
So am I.
Amanda French
Who were the primary advocates of implementing ROR at your organization?
Cory Schires
I would say it was the sales team and Brian Cody, our CEO. The sales team is obviously always talking to a lot of prospective customers and sometimes to current customers, and people are always asking for things. We’re very dutiful about keeping notes on all of that and tracking what people are asking for. So while we heard it from the sales team, they’re ultimately relaying customer requests. If enough people ask for something, we’ll probably build it.
Amanda French
You’re obviously very good about announcing new features in your products. We’ve seen you do that for ROR, and for other features as well. I’ve been reading around in your announcements, and they are frequent and detailed and impressive.
Cory Schires
Thanks. Again, credit to Danielle for marketing. At Scholastica, we all advocate for shipping features that are important to industry partners and improving our existing integrations to better support the flow of research. We like to stay connected with the broader publishing and research community not only to keep raising awareness of Scholastica, but also to support important initiatives like ROR, so it’s a win-win.
Amanda French
That’s great to hear. Even being fairly new to ROR, having been here a little over nine months, I could already tell coming in that awareness of ROR is not much of a problem, certainly not in the United States and Europe and Australia. We’re also doing a lot of outreach to Asia and South America, to the extent that we can, and that’s been terrific. But it has seemed to me that there is a lot of buzz about ROR. And I am glad to hear that it’s something you feel you can brag about.
Cory Schires
It solves a problem. And with all PIDs, the more people use them, the better they are.
Amanda French
That is so, so right. And while it’s always hard to say someone is absolutely the first, as far as we can tell, Scholastica is one of the first major service providers to do such a thorough integration of ROR, where it’s in more than one of your products. I’ve talked to a number of people at other companies that are thinking about it or working on it, and there are some other partial implementations or ones that are for specific customers. But anyway, congrats.
Cory Schires
That’s good to hear, though I am a little surprised. It was on our internal roadmap for, I don’t know, at least six months. It felt like we were saying “We’re going to get to this” for quite awhile.
Amanda French
The funny thing is that six months sounds fast to me! My certification has expired, but at one point I was a certified Agile product owner, and having worked on several software projects, especially in university libraries, I know that it’s very easy for things to sit on roadmaps for months and months and months and months. So, good for you! And now can you describe in general how you’ve implemented ROR in your systems?
Cory Schires
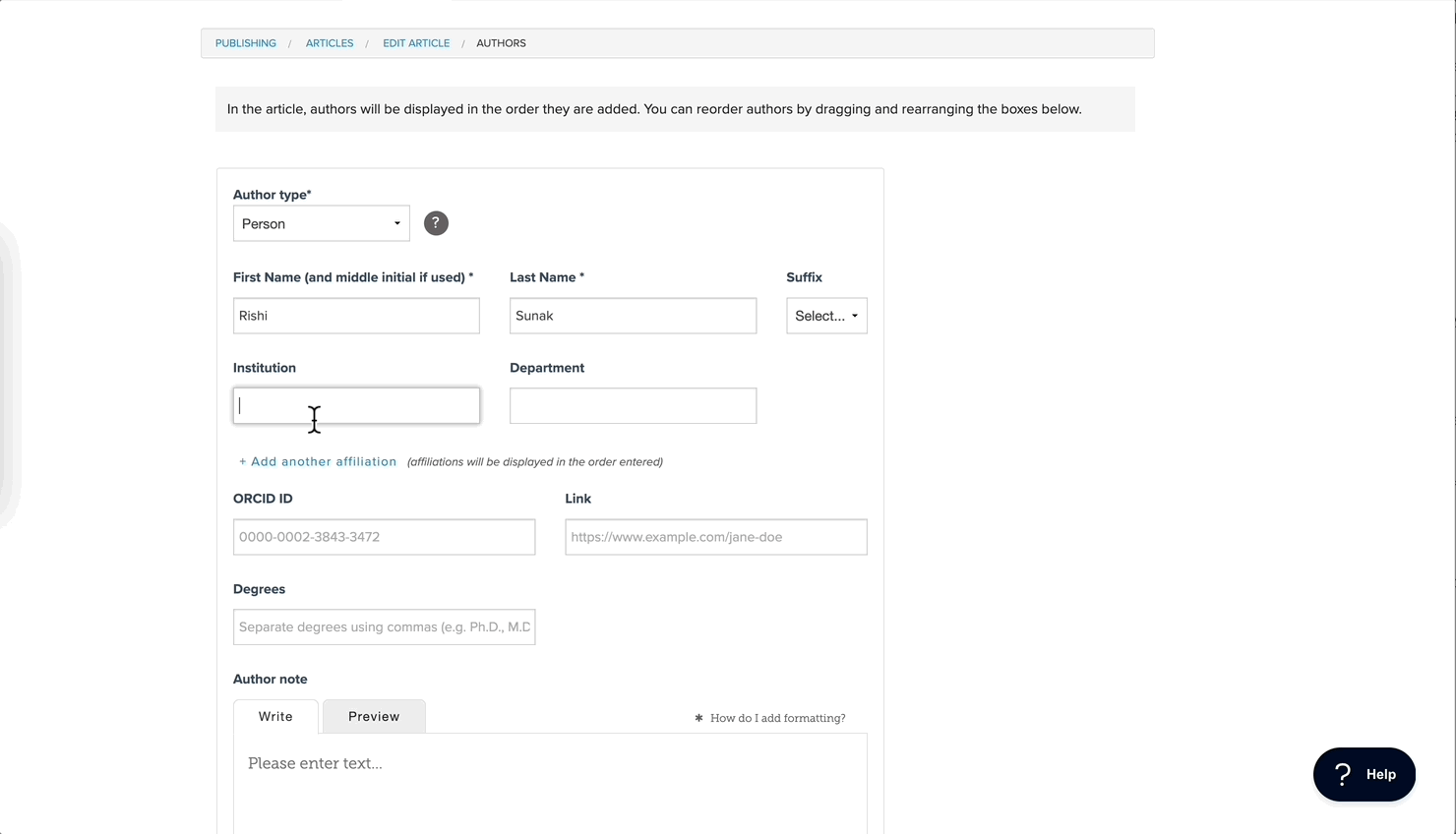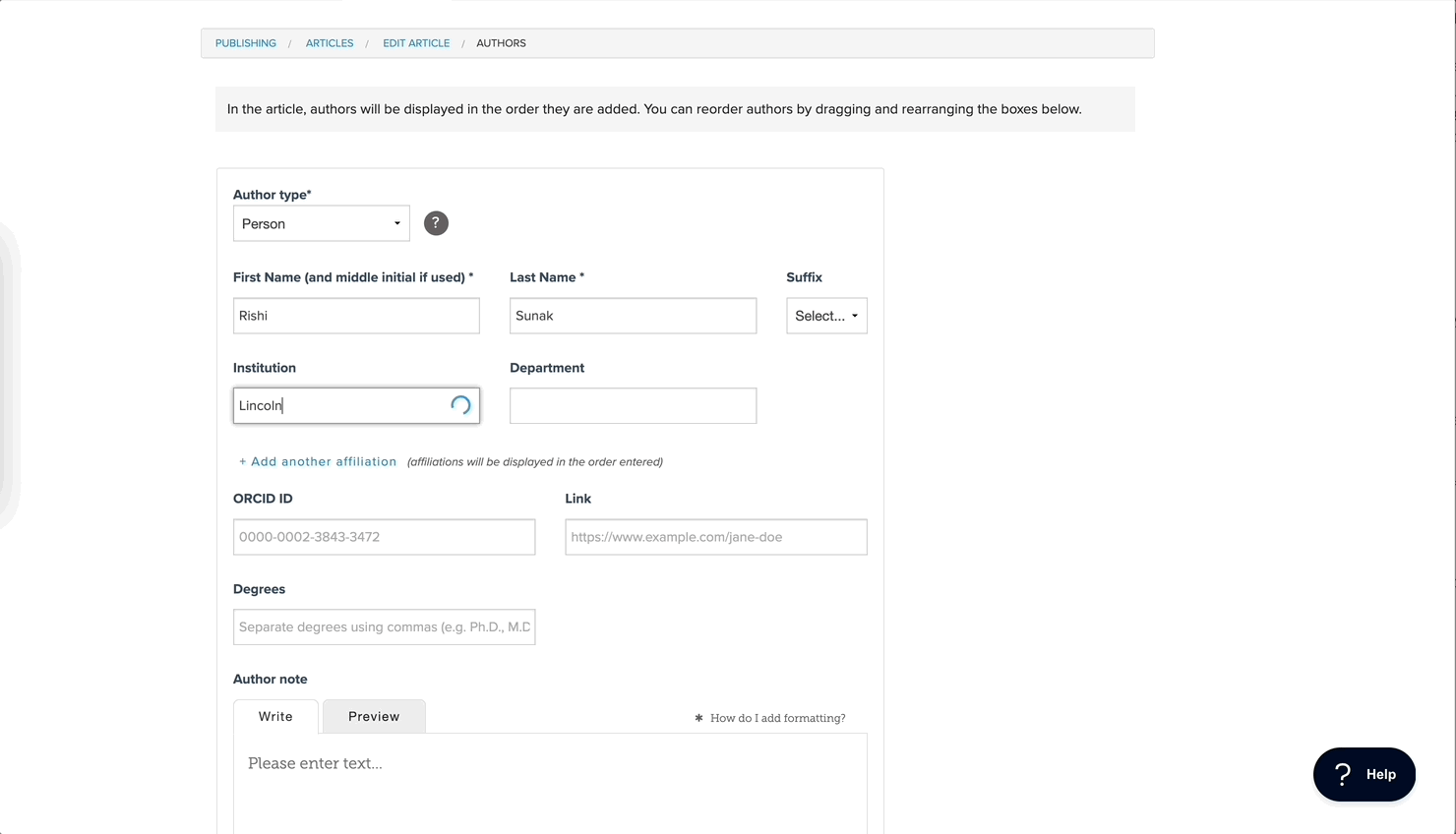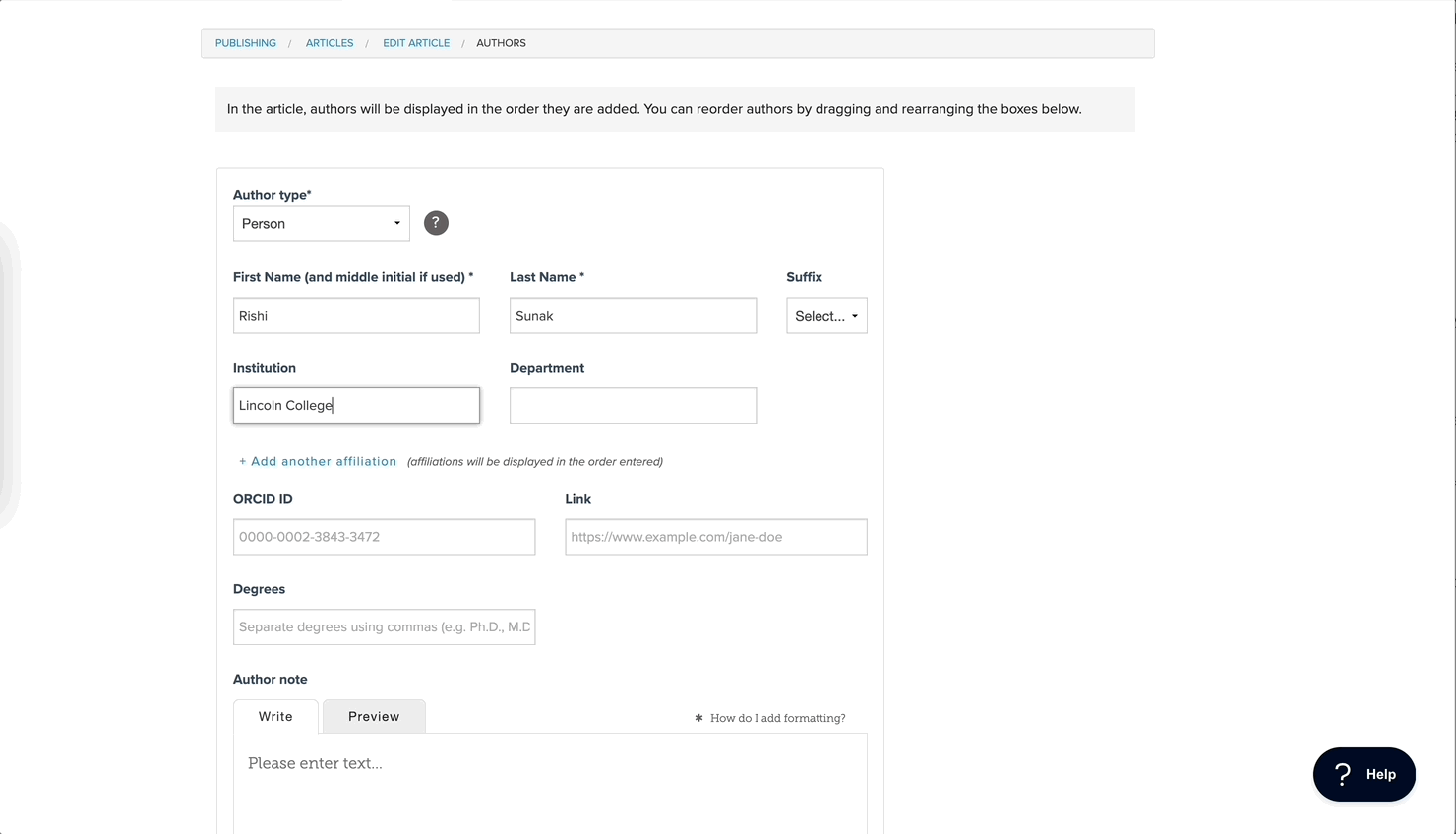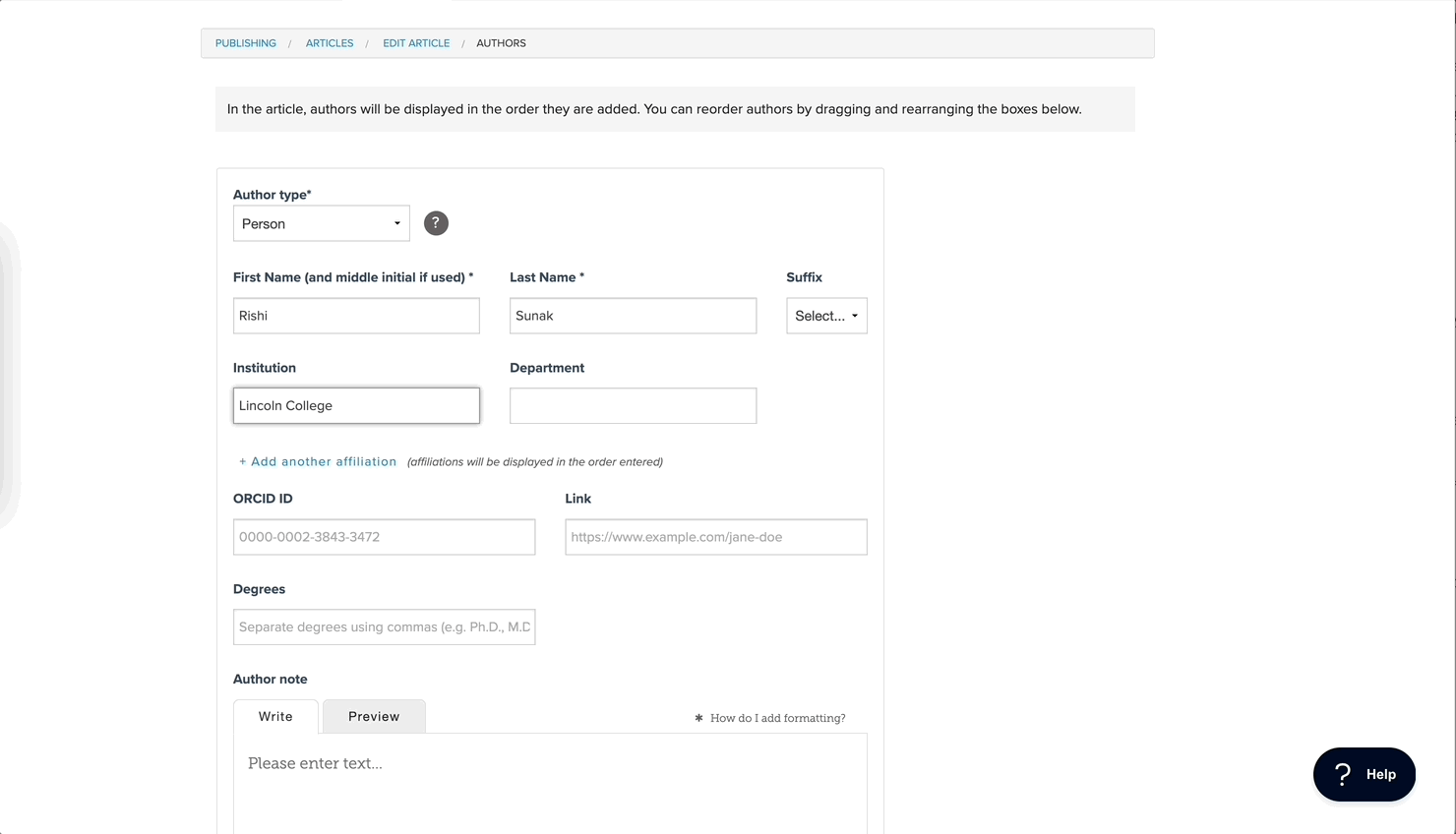
Sure. It wasn’t too difficult for us. One thing you already touched on is that we have separate products for peer review, production, and publishing. That means we had to put ROR support in at least two places: our manuscript submission form and the form that is used to create an article. So that was a consideration from the start. That actually kind of divided the project into two phases. First, you’ve got to collect the data; you’ve got to update your web forms, right? That’s the collecting part. Second, there’s using it – distributing it. Now that you have this data, you need to make sure that it’s getting into your Crossref metadata, that it’s getting into your JATS XML, that it’s getting into Portico and so forth. But anyway, you’ve got to make sure that anywhere you’re sending article data, ROR is going along for the ride.
And actually we did it in the reverse order. We did the second part first, which was to set up all our downstream integrations and different exports to understand and expect ROR identifiers, and we shipped that all the way to production. It wasn’t doing anything, but it was just there waiting to be useful. And then we did the first part, which was adding it to the various web forms so that we were actually collecting it. That allowed us to release it in two separate phases. You mentioned Agile project planning: we’re always looking for ways to break up an otherwise big project into a couple releases, if possible. So that’s the approach we took. That can be a good tip for anyone who’s similarly trying to keep this kind of project bite-sized.
Amanda French
Yes, that’s true: there’s the collecting of the ROR ID as one phase and the sending of the ROR ID as another phase. Actually, I know of several integrations that have done one or the other, not both. I know of people who are adding the ROR manually to their JATS XML, so they have people who as far as I know just copy and paste it into a template and send that to Crossref – smaller organizations. I also know of some systems that collect the ROR for internal use within systems and then don’t send it in DOIs to Crossref. The way you’ve done it is the ideal way.
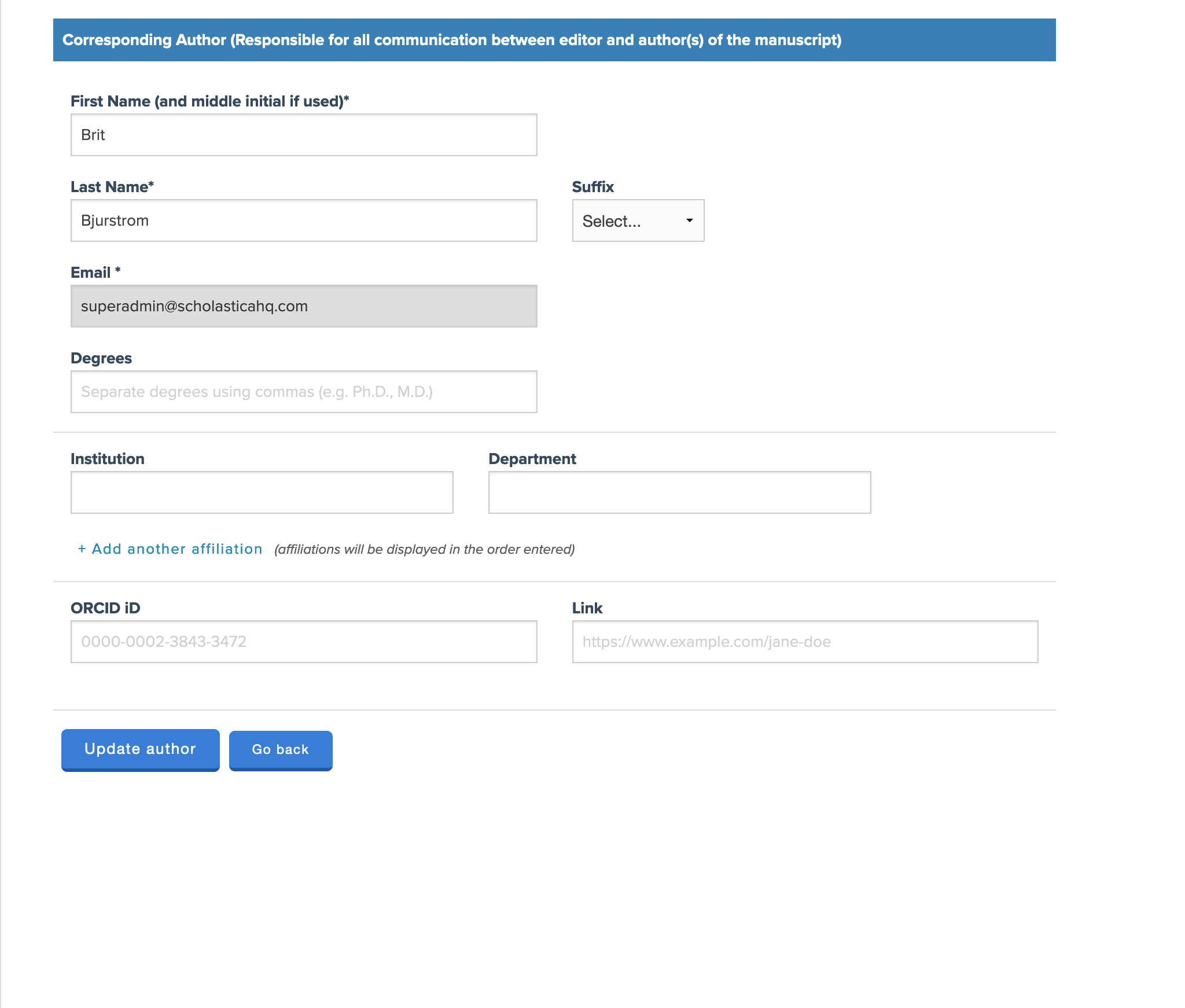
Tell me, in your manuscript submission and peer review system, are you collecting ROR IDs for all authors or just for the corresponding author?
Cory Schires
The corresponding author fills out the form on behalf of all the co-authors, and when they’re filling that out, the fields for each author are the same – or mostly the same. There’s a little bit of difference for the corresponding author, but they’re mostly the same. And the ROR integration part is the same. So yes, we collect it for all authors.
Amanda French
And how do you handle when authors have multiple affiliations?
Cory Schires
Even apart from ROR you need your submission form to understand that authors may have zero or more affiliations. If your form is assuming each author will have one affiliation, that’s not terrible, but it doesn’t mirror what we know to be real in the world. So you really need that as a starting point. And I don’t think it’s particularly novel, but there’s a standard “Add another” link you can click. You’ll see that in different online tools. The approach we took feels fairly conventional in a good way, I think: you don’t need to get too clever with something like that. We accept the institution name, and that bit is the ROR name, and that field is what we use to find and associate the ROR ID. And then we also have the department field, which doesn’t really have anything to do with ROR, but that gives you a place to put the other information that you might want to put.
Amanda French
That’s exactly the way we recommend to do it, so that’s great. How do you handle it when an author is affiliated with an organization that is not in ROR?
Cory Schires
Going back to what I said before, you need to get those two fields. We call it “Institution” and “Department.” As people are typing into that “Institution” name field, we have a user interface element that people call a “typeahead.” I guess you know what that is.
Amanda French
I had actually never seen the term “typeahead” before I started at ROR, but that is what we call it in all of our documentation and our demo and our demo code. I thought of it as a “suggest box” or something.
Cory Schires
It’s an autosuggest sort of thing, you know, like when you’re doing a search, it suggests results. Anyway, so as you’re typing in the name field, we’re suggesting results in that typeahead. And if they click on one of those results, great: it will fill up the field, and we’ll have made the association under the hood. In the interface, you could choose to expose the ROR ID or put a green check or something, but we didn’t do that. We are just collecting it unbeknownst to the users. And to answer your question about organizations that are not in ROR, because it’s a typeahead field, they can also just type whatever they want. They don’t have to pick something from that list. We did think briefly about requiring ROR IDs, but we decided against that.
Amanda French
We recommend against that, because while we do have a process for people to request a new ROR ID for an organization, right now it’s just a Google form to request a single new organization. And it does take us roughly four to six weeks to get those new organizations into ROR, because we curate those requests. We have to check and see, “Is this a real organization? Is it in scope?” So we ask people not to require a ROR ID in forms, because otherwise we’ll get requests from people saying, you know, “I can’t submit my manuscript, and I have to do it by tomorrow.” So kudos to you: exactly the right way to do it. And we’d love to build a process for collecting some of this data from ROR users, getting information on what these organizations are that people aren’t finding in ROR, to see if we can add them. We’d like to do that someday, but it’ll take a while to figure out.
Cory Schires
We’d be happy to send you a CSV of organizations that people have entered that aren’t in ROR.
Amanda French
Feel free to do that – we’d love to look at it. You can email it to me. That’s where we are right now: we’re on the “email us a spreadsheet” end of the spectrum of data collection methods, which is fairly primitive, but we’d definitely be happy for you to do that. So, just a couple more questions. What benefits to you and your users is this ROR implementation providing?
Cory Schires
I would say the benefit to the users is getting better metadata. It’s an obvious answer, but users don’t always know about metadata. They also might not think of metadata as a feature, but we do. At Scholastica, we care about taking steps to enrich metadata – like adding ROR IDs, for example, on behalf of our customers, so they don’t have to worry about the technical aspects of metadata collection or creation and can instead focus on maximizing the discovery benefits.
Amanda French
Right.
Cory Schires
We really tried to integrate ROR into every possible way that we send data, to Portico or whatever the case may be; we really tried to add it everywhere. And if we missed a place, someone will tell us eventually, and we’ll add it there as well. But that’s the main thing, is just the richer metadata.
Also, and there aren’t any short-term plans to do this, but this does give us the ability to do things that people have asked for occasionally. For example, “Oh, I’d like to see a list of all my past authors, and I would like to be able to filter that by institution.” We couldn’t do that well without a stable identifier to know which institution is which, so I think it opens the door for some possible new features for us. It also might be interesting at some point to query the data to produce something like a pie chart showing the breakdown of the institutions authors are coming from by Carnegie classification, for example. I don’t know that that would be anything other than merely interesting.
Amanda French
Sure, yeah. It’s interesting that you’re not showing ROR IDs to the users, and that you’ve said that whether users care about it or not, the ROR ID and that enriched metadata is a service to them, and a feature, and it might enable other features. I think ORCID originally thought that they would be a behind-the-scenes piece of technical infrastructure, and I think we thought the same at ROR, that it would be mostly implemented under the hood in the way you’ve done it.
But there are systems that do display ROR IDs to their users, and it is kind of nice, because you can click on the link and go see some concise information about that organization. ROR is a bit different from ORCID in that ORCID records have to be maintained by individual researchers, so they do need to see it, whereas ROR IDs are not maintained by individual institutions. So I think you’re exactly right that users don’t really need to see the ROR ID, but they will benefit from that behind-the-scenes tidiness and enrichment of the metadata.
Cory Schires
As I recall, we did talk about that: “Should we show it?” We also talked about that case where the user types in an organization that is not in ROR; we thought about putting something like a yellow warning saying, “This isn’t in ROR.” We even actually started to code that, but then we pulled it out of the plan, because as we were thinking more about it, it was clear that people were going to see it and they would think something was wrong.
Amanda French
I have seen systems where they display a green checkmark or something similar when the organization is in ROR, and when they do that they add explanatory text and sometimes a link to the ROR website, so it can work, but we’ve had some misunderstandings from that kind of implementation.
Cory Schires
“These three authors have green checkmarks and this one doesn’t: what am I doing wrong?”
Amanda French
Yeah, it’s like, “Oh, no, nothing is wrong.” It’s a perfectly legitimate organization, or the author is an independent researcher, or, you know, there are all kinds of legitimate reasons for there not to be a ROR ID for an organization.
Cory Schires
And we can layer that in later if there’s some reason to, but this is where we’ve started.
Amanda French
What do you hope ROR does in the future? What opportunities should we pursue, or what would make it easier for you and other service providers to adopt ROR? What feature suggestions or bug fixes do you have for us?
Cory Schires
The main thing is that I’m just glad ROR exists. There are all kinds of reasons why you would want to know what institution an author is coming from. Before ROR, I was aware of some of the commercial competitors, but they were prohibitively expensive for many smaller journals and more difficult to integrate. We work with bigger journals and presses, but we also work with many small journals, and the price was a concern for our customers. When ROR came out as something that was free and community-supported, that was super important.
But that doesn’t really answer your question. I would say one thing I like about how y’all have set up ROR is your approach to parent-child or nested institutions. Obviously, you can go super deep on that and get extremely detailed. And I think y’all have helpfully resisted the urge to go deeper than makes sense, in my opinion. I mean, people don’t always realize that: it’s kind of counterintuitive that there can be an inverse relationship between the richness of a dataset and its utility. It can get so granular, and that’s cool, but then it’s really hard to make any kind of inference from the data. It becomes like Borges’s map. It’s really exact, but it’s useless.
Carroll, Lewis, and Harry Furniss. Sylvie and Bruno Concluded. London and New York: Macmillan and Co., 1893. HathiTrust. Accessed 22 Mar. 2023. Influence on the one-paragraph Jorge Luis Borges short story ‘Del rigor en la ciencia’ (On Exactitude in Science), first published 1946.
When I was looking into that and thinking about that problem, I thought, “Oh, I like the approach they’ve taken here. I agree with this.” It made me feel like y’all are … well, the opinion aligns with mine, which is comforting to me.
Amanda French
Wonderful. I don’t know if you saw our recent blog post about hierarchies and relationships – we say some of those exact things. We found out that somehow people were under the impression that ROR didn’t do hierarchy at all.
Cory Schires
Yeah, that is what I thought initially. But I remember looking at the API and seeing, “Okay, yes, there are some relationships.”
Amanda French
You’ve been so kind about ROR when I asked you to give us constructive feedback! And hopefully, we’ll get to that. But honestly, I do think that is one piece of constructive feedback that we needed to hear, that we were mis-communicating about what ROR can do in terms of parent-child institutional relationships. People often ask us about university departments in particular, and we don’t do university departments, but that doesn’t mean we don’t do organizational hierarchy at all. We absolutely do that: for both parent-child relationships and related organizations.
That’s why we’ve just put out that explainer blog post, and we’ve also beefed up our documentation to say, “Yes, we do hierarchy and relationships,” so that you don’t have to look at the JSON in the API in order to figure it out. And we didn’t have the relationships in our search interface for awhile: we just added that a few months ago. Since a lot of people look at ROR just in that browser search interface, they didn’t realize the relationships were there. And we really do think that the degree of granularity we have, which is not as deep as some other organizational identifiers, is a feature, not a bug.
Cory Schires
I agree with that. Keep it simple, or at least relatively.
I might have more feedback on ROR as we start to use it more internally, but one thing I would say is that you should invest in the resiliency of the API and of the organization. This is a small example, and I love Crossref, don’t get me wrong, but we had some tests in our test suite that hit the Crossref API, and we had to disable those by default because sometimes the API goes down, and then our test suite is failing and causes problems for us. The ROR API is increasingly useful, I think, and we service providers need it to work for integrations.
Amanda French
That is great advice. Our API has had wonderful uptime so far, and we have a little API heartbeat, so you can just send a little quick query to that to see if the ROR API is OK. But we definitely have been seeing increased use, and increased use, and increased use, which is great. We want that to happen, but it does mean that there are more costs. As you might know, we are supported by three organizations, and DataCite is the one that pays for our technical infrastructure.
One other thing about the API. As you’re obviously aware, you can get the ROR data dump and query that or you can hit the API, and we evaluated both approaches. Specifically, we were looking at, “Is this API going to be fast enough and reliable enough?” because we would prefer to hit the API than keep our own copy of the data, and in our testing, it was good. So that’s great.
Amanda French
And now that we’re updating the ROR registry about twice a month, if you’re using the data dump, you’ll have to make sure that you have the latest version of the data. You can get that programmatically by querying Zenodo. But if you’re querying the API, you don’t have to worry about that: you’re just getting the updated data automatically.
Cory Schires
Sure.
Amanda French
Is there anything else you’d like to say before we wrap up?
Cory Schires
One thing I would say is that this was a team effort. I didn’t work that much on the ROR project. Brian Cody, our CEO, did most of the project planning and actually most of the spec writing, which is not usually how he spends most of his time, but he wanted to help get this one done. And several different developers worked on it. Specifically, Tatum Szymczak really carried it across the finish line. A whole bunch of people worked on it, and that’s important.
Amanda French
Yes, it is! Well, thanks for talking with me, Cory. It was nice to chat.
Cory Schires
I appreciate your time. Thanks for involving me. Happy to be doing this for ROR.
Questions? Want to be featured in a ROR case study? Contact community@ror.org.