Case Study: ROR in DataSalon's MasterVision and PaperStack
By Amanda French | May 10, 2023
In January of 2022, DataSalon announced a full integration of ROR into its scholarly publishing analytics products MasterVision and PaperStack. DataSalon’s Client Services Director Andy Dobson sat down with us to tell us all about how they draw on fifteen years of data experience to match organizational affiliations in publisher data to ROR IDs.
Key quotations
“We’re really interested in data standardization and cleansing: that’s central to what we do, so we’re all very aware of the importance of having a free and open standard reference dataset for identifying organizations and for supporting some of the other datasets that get loaded into our products. Open source data is key to our ethos.”
“And if you’re moving into OA, and you’re not understanding a standardized picture of your customer hierarchy, and you don’t know how many articles are coming out of the University of Oxford and how much they should be paying in article fees, then that becomes really tricky. There are potentially significant financial implications, on the customer service side, of not having a dataset that allows you to clean up and standardize all of those customer pictures within your data.”
“ROR does open up new possibilities for us, such as integrating some of the other systems that are around at the moment. We’re currently looking at bringing OpenAlex IDs into PaperStack. That should be really straightforward, because you can use the ROR IDs to retrieve the OpenAlex IDs through their API.”
– Andy Dobson, Client Services Director, DataSalon
Amanda French
Thank you so much for agreeing to interview with us. Can you start by telling us your name, title, and organization?
Andy Dobson
I’m Andy Dobson. I’m the Client Services Director at DataSalon.
Amanda French
Tell us about DataSalon.
Andy Dobson
DataSalon was originally set up in 2006 by Nick Andrews, who is our Managing Director, and Jon Monday, our Technical Director. They had been working together managing large-scale IT projects for major publishers and retailers, and had first-hand knowledge of the technical systems and services used by publishers. DataSalon was born out of the challenges, needs, and requirements faced by the publishers they were working with.
Our original product is MasterVision, and that’s really core to everything that we do here. Not only was it the product that gave the business its start originally, but it also became the basis for a lot of the services we provide, such as PaperStack, and the data quality work we do around cleaning and standardizing data. MasterVision was developed in response to the problem of establishing a joined-up view of multiple databases without having to replace or upgrade existing systems. From its launch the system was immediately adopted by OUP and the BMJ and was acclaimed as solving a significant business challenge for a fraction of the time and cost of conventional solutions. I’m pleased to say that both OUP and the BMJ are still clients!
We’re quite a small company, but we’ve got a good long-term client base at DataSalon. People like the way we work, and they continue to work with us. We have a very collaborative relationship with our clients. We help them solve a lot of the challenges around data cleansing, integration, and analysis of their data in a way that’s significantly faster and cheaper and more flexible than conventional approaches. And as an organization we’re quite small, but we’re extremely agile, so we’re very responsive in terms of customer service, and we’ve got an excellent understanding of the scholarly publishing industry.
I’ve previously worked at Elsevier and Ingenta, and all of the staff have worked at various companies within scholarly publishing at some point. So although we’re an IT company, we’ve very much got one foot inside scholarly publishing.
Amanda French
So you’re saying that you’re small but mighty?
Andy Dobson
Yes, small but mighty. Exactly. We like to think of ourselves as being a bit different, innovative, and extremely effective. We’re a 4-day week employer, and we’ve always worked, in the main, from home. Even before the COVID days, staff have generally worked from home, so we’ve been quite forward-thinking in that sense.
The key to our success has been in ‘growing’ each client’s system directly from the source data, rather than creating them through the traditional time-consuming (and expensive) process of analysis - design - implementation. This same innovative principle lies behind all of the services we now offer, including PaperStack. We offer a very collaborative way of working with the data that is customized to the needs of the publisher. So right from the setup of a given build of MasterVision or PaperStack we work with our clients to develop the tools alongside the specific requirements of their data.
There are a lot of similarities, obviously, across scholarly publishing data. Typically it’s subscriptions data, memberships, usage, denials, etc. – all of those things that we’re familiar with. But there are, within that, very individual requirements related to their business models and company goals, so we work with each one individually to give them what they need.
Amanda French
Great. Can you tell us a little bit about first MasterVision and then PaperStack? What kinds of things do they provide for publishers?
Andy Dobson
MasterVision was our first product and it provides publishers with complete customer insight via a fast and user-friendly hosted service. It painlessly merges all of the valuable data from different source systems providing a ‘single customer view’ of all interactions with a customer. The interface itself is a standard across all of our clients, but each one has been tailored to their individual requirements. There wasn’t anything doing that for publisher data at the time MasterVision was created, and I still don’t think there is anything that offers that in quite the same way.
We don’t look to replace any of the source systems. Publishers will still pick and choose the most effective systems that they want for fulfilling their needs, ie. their platform hosts, their membership database, fulfillment, and peer review systems etc. The integrity of that data is kept and what we’re doing is providing a read-only interface onto all of that data. So we’re effectively joining up all the different instances of the given customer, whether that be an individual or institution, into a single record, and maintaining and describing that customer hierarchy for detailed analysis. It comes in really useful if you want to analyze things like “How many authors have I got submitting to our journal from a given institution?”
Amanda French
I can see why you would be interested in ROR, then.
Andy Dobson
Yes, exactly. So having a reference record to tie customers to is really important, and having the hierarchy of those customers offers vital context. MasterVision is predominantly a sales and marketing tool, and allows publishers to look for sales opportunities and to provide better customer service through having a deep understanding of their customers. If you’ve got customer data in multiple datasets living in multiple systems, it’s time-consuming to go in and query each of those separately. Whereas pulling all those together into a system, that can’t be broken by end users, allows staff to see exactly what’s going on on a customer basis for all aspects of the relationship. And it’s extremely quick and simple to get answers. So rather than getting IT involved to run complex queries across multiple systems, the end user, even if they’re non-technical, can do that themselves. You can put together quite complex queries with MasterVision: “Who does XYZ, but doesn’t do A or B?”
Amanda French
It sounds like you anticipated data science before “data science” was really a term.
Andy Dobson
Yes, we’ve been doing this for quite a long time now. We feel like we were one of the first to really promote data quality and data cleansing. And as I say, many clients stay with us for a long time.
Our other product, PaperStack, works on a similar basis. It’s providing publishers with a complete reporting suite for the scholarly submissions process. It is fully integrated with major peer review systems including ScholarOne and Aries Editorial Manager, meaning there is almost zero publisher overhead to get up and running. As a standard part of the service, data from peer review systems is also automatically linked and enhanced using industry data from ROR or Ringgold, Funder Registry, ORCID, and Crossref - all helping to maximize reporting insights. This results in a clean, standardized and comprehensive cross-journal view, available at the institutional, funder, author, and article level. As far as possible PaperStack aims to provide a service with zero overhead in terms of effort on the publisher’s part. What we’re doing is providing a contextualized and enhanced view of their peer reviewed data, including details of where rejected articles end up.
By “contextualized,” I mean that we’re using ROR, Ringgold, Funder Registry data, ORCIDs, publication information from Crossref, etc., for building out a comprehensive view of not only the timeline of a given article, but also all of the other big pieces of the puzzle: What are the affiliations of the authors and the editors? What is the hierarchy in terms of organizations they’re affiliated with now? How was that then and what does it look like now? How long did it take an article to be accepted? Where did it ultimately get published? We use all that data to create a set of standardized reports that publishers can use, as well as helping them to create additional customized reports that they might want to design to meet their business needs. So PaperStack provides extremely detailed, responsive, and visually appealing reporting of their scholarly submissions.
Amanda French
And do you think that’s also primarily used by sales and marketing teams at publishers? Or does it have a different purpose?
Andy Dobson
It’s primarily editorial staff that use PaperStack, but there are applications for sales and marketing in terms of some of the reports that could be created. Additionally you could add in any additional customer data to enhance the overall picture. Because it’s based on MasterVision, it potentially means clients could load in usage and denials, APC data etc. to add further value to the submissions picture.
Amanda French
Great! I think I’ve got a sense of what they do now. Tell me, who were the primary advocates of implementing ROR at your organization?
Andy Dobson
I would say all of us, from the customer service side to the product managers, to the technical team, and Nick himself. One of our product managers managed the implementation, but the requirements from our clients meant that there was a lot of support and interest from all parts of the business, really, in getting it within the products that we use. We’re really interested in data standardization and cleansing: that’s central to what we do, so we’re all very aware of the importance of having a free and open standard reference dataset for identifying organizations and for supporting some of the other datasets that get loaded into our products. Open source data is key to our ethos.
Amanda French
That’s wonderful. You’ve mentioned the importance of a free and open dataset, and your products do use Ringgold as well, as you’ve mentioned. Can you talk a little bit about what ROR does that Ringgold doesn’t? And vice versa, if you like, too: what does Ringgold do that ROR doesn’t?
Andy Dobson
Yes. Just to go back slightly: as an organization, we’ve always used an org dataset for standardizing and linking academic institutions within MasterVision and PaperStack. It’s key for what we do. And while that’s not completely necessary for the products themselves, it does provide an underpinning for delivering a comprehensive and reliable single customer view. In the past we’ve always used Ringgold for those clients that license the Ringgold data. But there are a number of clients for whom the Ringgold dataset isn’t affordable, practical, or streamlined enough for their purposes. Our client base is pretty much half and half, I would say, between the publishers that used Ringgold and the people that didn’t have anything. Back in 2014 we felt that there was a big need for us and our clients to have access to a free and open dataset. I don’t know how familiar you are with OrgRef, but we launched OrgRef in 2014.
Amanda French
I’m somewhat familiar with it.
Andy Dobson
Back in 2014 we launched OrgRef as the first free and open dataset about academic institutions. We worked mainly to establish some useful metadata around academic institutions and a hierarchy picture to provide a way of standardizing that information and making it available to the wider community. I think when OrgRef was launched there wasn’t any other free and open institutional ID available. We gave it away for free, and we used it within our products. We received a lot of useful input, from our clients, to develop the dataset further.
It was well received, but obviously the resource that we could attach to it was a lot smaller than commercial offerings, so there was a sizable gulf in terms of the volume of records that sat within the dataset. Ringgold had about 400,000 or so at the time, and we had I think about 80,000 – although those 80,000 pretty much covered all of the likely subscribers to academic content. Anything more than that tends to include orgs a lot lower down the institutional hierarchy. Not all scholarly publishers are going to be interested in seeing a secondary school in the middle of California that’s not likely to buy a subscription. There is a lot of data within Ringgold, for example, that won’t be necessary for the needs of the smaller publishers.
Amanda French
We’ve definitely heard that before, and of course we appreciate it. ROR currently has about 105,000 records.
Andy Dobson
OrgRef itself was extracted from structured information on Wikipedia and other open resources. And, as I say, it aimed to cover most of the important academic and research organizations. The metadata was similar to what you would see in Ringgold – things like name, country, URL, standard IDs like VIAF. We made OrgRef free and open for people to download. It was maintained by us and updated on a monthly basis. That probably was less frequent than some publishers would like, in the sense that they might be wanting to update their customer data on a more regular basis. And so we managed that for a while, and then Digital Science launched their GRID dataset, and they had more resource available to put into that. Their metadata was slightly richer. So we assisted GRID, and they used the OrgRef data to enrich the GRID dataset.
Amanda French
That was very generous of you.
Andy Dobson
Well, it was free and open anyway! But we stepped back and let them carry on, just because we’re quite a small company. We had other products and projects that we were more focused on. The main goal was really to have an open data set that could be used by those who couldn’t afford Ringgold and that could be used within our products. If someone else was willing to take that on, that was fine by us.
Amanda French
They were very helpful in setting up ROR.
Andy Dobson
Yes. Although it’s great to do it as an open resource, I suspect both Digital Science and ourselves partly did it for selfish reasons as well as altruistic reasons. So I think when it gets to the point that someone else is prepared to take over, you say, “Yeah, that’s great, thanks.”
Amanda French
Right.
Andy Dobson
And ROR probably sits within that Crossref space better. A lot of what we were doing was pretty much automated, although there was some manual input. As I understand it, there’s more manual input on the Ringgold side for digging out the right record, making sure that that is the right address, etc. They’ll resolve institutional lists that you might want to provide to them, and they do some other bits and pieces that sit outside of what is possible with automation alone. It comes down to, I suppose, publishers getting what they pay for. But having a free and open reference dataset is great for everyone.
Amanda French
Great. Can you take us through some details of what you’ve done in your ROR integration? How did that process go? What does that look like within MasterVision in particular, but also PaperStack?
Andy Dobson
Yes, okay. The ROR integration was very straightforward. We use ROR in both our core services, MasterVision and PaperStack – both of these join together data from multiple sources to give a complete picture of customer activity (for the former) and the editorial process (for the latter), and to do that we need to identify which records relate to the same institution or individual. Matching with ROR means we can link up all the activity by a particular customer even if the data doesn’t have any other IDs or if multiple customer IDs have mistakenly been assigned to the same institution – which happens a lot!
It also means we can standardize the data – we use the name and location information from ROR for the main display, so that the format is consistent across all data sources.
We do the matching not just for institutions but also for individuals, to link them to their associated institution, which means that our clients are able to analyze data available at the individual level (like article submissions or pay per view purchases), as well as at the institutional level.
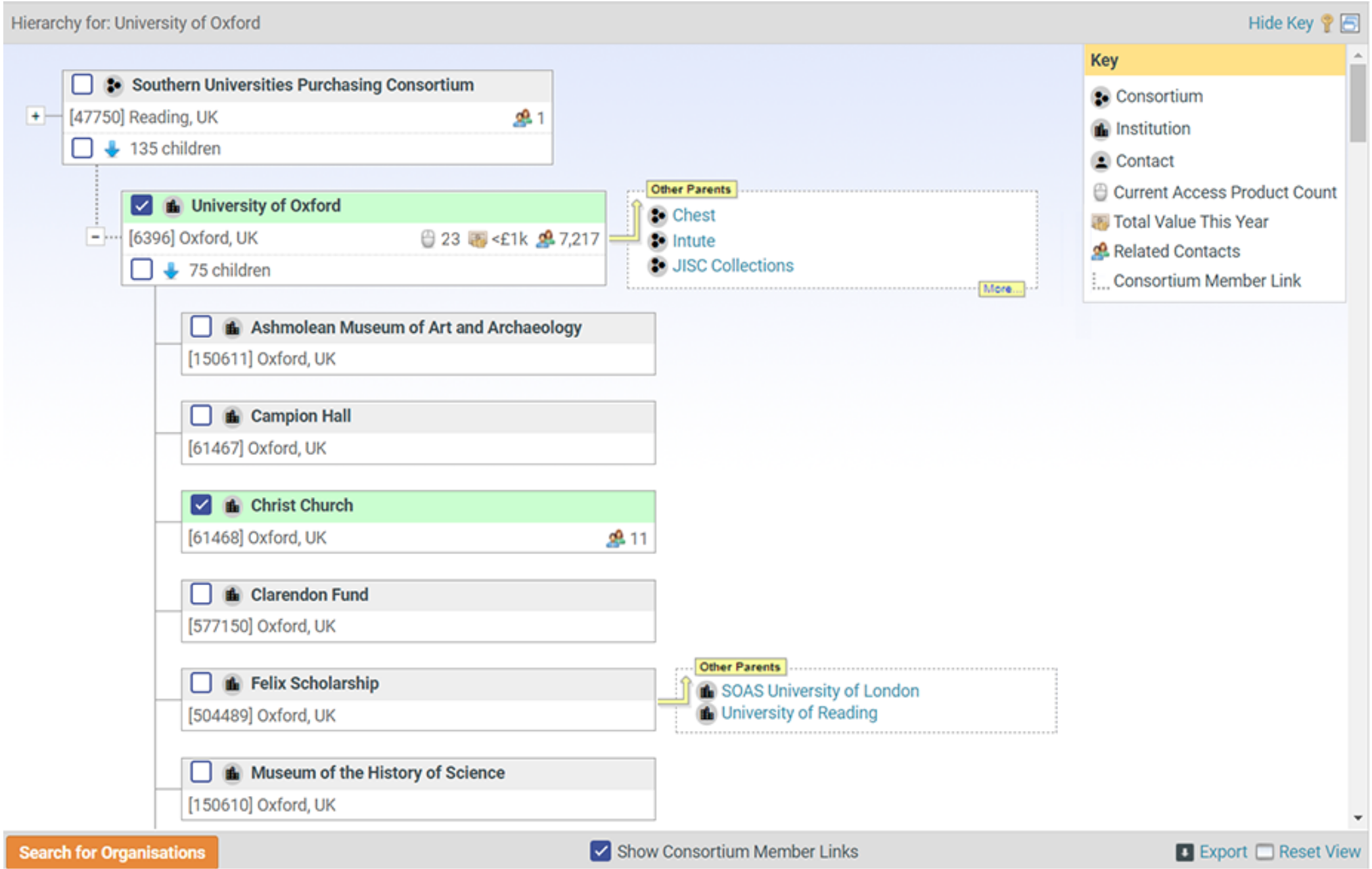
We also use the parent/child information included in ROR to show the relationships between records, with a family-tree style hierarchy viewer. Making use of hierarchy data allows clients to achieve complex uses around activity, be it funding, article submissions, content purchasing at any level in that hierarchy, or for example, do institutions access content that their associated authors submit to.
Amanda French
And how did you match the ROR IDs to the existing institutional data?
Andy Dobson
It was quite simple to do because ROR data is very much similar to GRID. We would just use ROR in the same way as the GRID data that we’d previously been loading. Because ROR contained exactly the same data as GRID, including GRID IDs, it made it easy for us to test and implement. We migrated each client site, and we were able to check that the matching tools that we used were always giving the same results as ROR IDs. There’s lots of challenges around that, particularly using real-life data. Using a reference dataset means that we can standardize information within the real data from publishers, which is pretty messy most of the time and not consistent from system to system. There’s things like different name forms, different location information, different data structures, data entry errors, missing location information. But a lot of those things we’d already addressed and developed within our own matching tools.
Amanda French
Gotcha.
Andy Dobson
Part of what we do is provide matching services to publishers as well, so that sits within the tools that we have. As we load data, we will match to the reference dataset where we can. Where there are IDs that we can match, we will use those. If not, we will use our own tools to auto-match against that reference dataset. So we’re using that dataset in two ways. One is ‘as we find them’, matching customer IDs that might sit within the publisher data to the reference dataset, and the other is to match the metadata to the reference dataset.
Amanda French
And when you say customer IDs, what do you mean?
Andy Dobson
If the fulfillment data, for instance, that we receive from a publisher contains a ROR ID, or a Ringgold ID, we’ve immediately got a match to the full ROR or Ringgold record. So where those are used in the publisher data, we will match that to the standard records.
Amanda French
Gotcha.
Andy Dobson
So for example, in their fulfillment data, they might have a customer specific ID. Whereas in their usage and denials data they might have a ROR ID which identifies a given org. Where we can pick out those IDs, we’ll use them, but we’ve got our own matching tools that we’ve developed over the last 15+ years that allows us to do automated matching to create a link to the ROR data, where those IDs don’t exist. The benefit is that all those different instances of “University of Oxford” will match to one “University of Oxford” record.
Amanda French
Right!
Andy Dobson
We’re doing work on our side to match to those standard records. We use a variety of strategies like fuzzy matching; lists of alternative names to supplement the ones in ROR; lists of alternative names to ignore (so that common acronyms shared by more than one organization don’t lead to incorrect matches); lists of synonyms for typos and US/UK spellings; mappings of state and country codes to full text; inferring missing information from the country name; and matching email and web domains against the organization URLs in ROR.
Amanda French
Wow.
Andy Dobson
We are very proud of our auto-matching tools which can link ‘real world’ (i.e., messy!) publisher data to the correct ROR records with an impressive degree of accuracy. The rules and exceptions in play there have been refined over many years. For example, ROR ID https://ror.org/04cvxnb49 (Goethe University Frankfurt) brings together many different names:
Goethe University
Goethe University, Frankfurt
Goethe-Universität Frankfurt am Main
Goethe-University
Johann Wolfgang Goethe University
Amanda French
It’s fascinating, and you do have a a nice blog post detailing some of what you’ve you just told me – your “secret sauce.” We’ve found that that matching is a thing that many people and organizations want to do, because there are a number of organizations that, as you say, had nothing, and so they have a pile of messy text strings, and we do have tools and methods that we recommend for doing that. But it’s been remarkable to me in the last few months to discover how many different methods people are using. A lot of people are building their own systems for doing that, and they don’t have your fifteen years of experience doing that matching with other things.
Andy Dobson
What we’ve got in place is very well tried and tested now and works really well in real-life scenarios. There can be multiple different versions of Oxford University that might sit within the different datasets that we pull in, whether it’s “University of Oxford,” “Oxford University,” or indeed a subunit that sits below that top level, something like the Bodleian Library, which would be considered as part of the University of Oxford.
Amanda French
Is the matching that you do entirely automated, or is there any human checking afterward?
Andy Dobson
There is some manual checking that goes on, but it’s predominantly automated. I would say probably 90% is automated. There is a manual checking process where we’ll go through and make sure there’s no obvious incorrect links there. That gets used in a couple of different ways. The first is on the fly, during the build processes for our two products, MasterVision and PaperStack. What we’re doing is we’re taking weekly data uploads from the publisher and then rebuilding those sites for them on a weekly basis, sometimes on a daily basis. Part of that build process will be running that matching against the latest data that we receive so that the publisher has the latest, best, single standard record for a given institutional customer based on the latest data available. In that sense, it’s working in an automated way as part of the build process, so if there’s half a dozen versions of “Oxford University,” then we would link those up during that build. Obviously, if there are IDs that we can use from Ringgold or ROR, then we can use those in the build process for creating that single standard record.
And then we also use the auto-matching tools that we have to provide additional services to publishers. Some might not be MasterVision or PaperStack clients. They might come to us and say, “We’ve got 10,000 institutional records that are just a complete mess from this particular database that we’ve been keeping for the last ten years. Can you deduplicate it? Standardize it? Match it to ROR?” And we can do that for them. It’s part of the service that we can provide as well.
Amanda French
Oh, that’s interesting! I didn’t know that. As I said, we actually have been hearing a lot of desire for that from different entities.
Andy Dobson
Yes, it’s a pretty straightforward process. By its nature it’s not 100% accurate, because often the data is so messy and what’s available just isn’t clear enough that some matching is just not possible. Oftentimes the data might have been collected over a period of years from lots of different places. There might be someone who has been to an industry show that’s just taken some notes down and has gone, “Well, you know, X university has got this address,” and then it sits within the database and no one knows what to do with it or how clean it is. So, yes, we often do projects for people where they want matching services to things like ROR or Ringgold if they license that.
Amanda French
You’ve said that the matching is not 100% accurate and that 90% of the matching is done automatically. Do you have any rough metrics that you know or can share about how accurate your matching is if you just do it automatically?
Andy Dobson
That’s a good question.
Amanda French
I know it’s hard to tell.
Andy Dobson
It’s tricky, because it depends on what the original data is like. Sometimes the matching might be 90%, sometimes it might be 70%; it just depends on how clean the input data is. But I would say around 80% is probably right.
Amanda French
And then, whatever the gap is, you’ll check that manually?
Andy Dobson
Well, it depends on what the client wants us to do. If they want us to do some manual work to try and fill in some of the gaps, we can do that. However, oftentimes an automated job matching a large chunk of data that otherwise couldn’t be used is good enough. Also, in some cases, if the data is really messy and sparse, and there is really not much evidence to allow us to make a match, then even with some manual input it would be difficult to have a match that you were 100% sure was the right one.
Amanda French
Right, because you just can’t tell what people mean. What do they mean?
Andy Dobson
Well, there are two big “York University’s” in the world. There’s one in Canada and one in the UK. There might be another one somewhere as well. If someone’s put “York University” and there’s little additional contextual information, you wouldn’t be 100% sure on which one they meant. So in some cases there’s some ambiguity there even when you get down to a manual level, because you just wouldn’t be able to tell which was which. There is an element of not having all of the information to allow you to be 100% accurate. We could literally be receiving a file from someone coming to us and saying “We found this file lying around on an old system. It has 10,000 names, and we don’t really know what to do with it. Can you do something?” So the starting point can often be challenging.
Amanda French
Got it. Let me ask you, too, how do you get the newest ROR data? Are you using the ROR API? Or do you get the ROR data dump?
Andy Dobson
We get the ROR data dump. We do use APIs for our PaperStack service when it comes to actually loading certain information. We use the ScholarOne APIs and the Editorial Manager API for collecting the data. However, we use the ROR data dump itself for loading into our services.
Amanda French
We are doing releases now at least once a month, usually twice a month. Do you have a programmatic way of getting those new updates to ROR, or are you just redownloading it from Zenodo every time?
Andy Dobson
We download it on a monthly basis, so whenever there’s a new one that comes out, we will pick that up and then apply it to the data that we’ve got.
Amanda French
Perfect. Just a couple of more questions. What do you hope ROR does in the future? Do you have any bug fixes, feature suggestions, advice, requests?
Andy Dobson
Our main concern previously was that there was no concept of inactive organizations, so it’s great that that’s been addressed. Going forward, I guess the best thing from our point of view would be adding new records just to increase the scope of the dataset.
It’s also key for us to keep the organizational hierarchies lean and relevant. As we talked about, having too many layers just takes away the usefulness of it and muddies the water a bit. You don’t need to know ten layers down what’s going on, because it’s likely not important or not relevant. That’s probably the main thing from our side, really, just for what we do, because that allows us to keep things like hierarchies within MasterVision and PaperStack understandable. If you’re looking for a sales prospect, or you want to understand at what level a subscription’s sitting at, or you want to know what authors are submitting at what institution, you don’t need many levels. You want to know those direct relationships, and maybe one or two layers down, but you don’t need to know that someone worked in a department of a library at the college of X university, which probably isn’t going to be particularly relevant to the sorts of analysis you want to do as a publisher.
Amanda French
What I’m also wondering about is what the business case for ROR is – for you, but also for publishers or other entities. How is ROR adding value to for-profit enterprises, given that it itself is free and open?
Andy Dobson
It comes down to the standardization of your customer data and to have a unique way of identifying a given customer / organization, within the sphere of your relationship and within scholarly publishing more widely. If you can’t associate all of your customer activity to a standardized picture of each organization, then what you’re left with is a very messy picture that is difficult to understand, and it’s very time-consuming to analyze and get into the guts of what your relationship with them ultimately is. If you’ve got multiple versions of an institution that you’re not tying together in a single record, then you don’t know, potentially, the full value that X University is getting from the deal.
For example, if a customer is referenced differently within both COUNTER data and fulfillment data, and you can’t join those records together, then you’re not going to be able to understand how much use they are making of their subscriptions. It also has a big impact on the customer relationship. When it comes to things like renewing sales, if you can’t actually tie up all of the different sublevels of the hierarchy of Oxford University to the top level, you could end up trying to sell things they already buy and it becomes a very untrusting relationship.
Amanda French
Yes indeed.
Andy Dobson
If you’re making a decision as a library based on how much content is being used, then you want to make sure your usage numbers align with what the publisher is seeing. And as a publisher, if you’re not able to present consistent numbers because you’re not able to tie up usage of the Bodleian Library with the University of Oxford, then it becomes a very difficult conversation. It’s like any customer relationship: one needs to feel valued and fully understood. None of us want to be mistaken for somebody else!
Amanda French
Definitely.
Andy Dobson
And if you’re moving into OA, and you’re not understanding a standardized picture of your customer hierarchy, and you don’t know how many articles are coming out of the University of Oxford and how much they should be paying in article fees, then that becomes really tricky. There are potentially significant financial implications, on the customer service side, of not having a dataset that allows you to clean up and standardize all of those customer pictures within your data. Having access to ROR and services like MasterVision allows publishers to continue to maintain and use their existing databases, and the imperfections therein, whilst being confident that they can clean and standardize data in an effective and economical way further downstream.
Amanda French
Right. We hear that a lot, that collecting beautifully structured, accurate metadata at the beginning is the ideal, but it just can’t always happen that way. Particularly in the case of affiliations, which were collected so often just in a text field, it can be very difficult.
Andy Dobson
Yes, exactly. While we would always recommend putting good data governance practices into place, that is not always possible or affordable. Having access to services that allow one to get the most out of what one has is the next best thing.
Amanda French
Yep. That’s about all I have for you. What else do you want to say about ROR or your implementation of ROR?
Andy Dobson
I think I probably covered most of it. ROR does open up new possibilities for us, such as integrating some of the other systems that are around at the moment. We’re currently looking at bringing OpenAlex IDs into PaperStack. That should be really straightforward, because you can use the ROR IDs to retrieve the OpenAlex IDs through their API. So that’s one of the benefits of having the ROR IDs and the mappings that we’ve got in place on our side. It’s opening up some other possibilities for us, which is nice. But in the main, having that free and open data is beneficial to everyone!
Amanda French
Great. Well, thank you so much again for doing this with us, Andy.
Andy Dobson
Thank you for the opportunity.
Questions? Want to be featured in a ROR case study? Contact community@ror.org.