Case Study: The Curtin Open Knowledge Initiative and ROR
By Amanda French | January 17, 2024
Professor Cameron Neylon of Curtin University talks telephones, power outlets, chat services, persistent identifier education, federated versus centralized curation, providing actionable information to universities, and why the COKI Open Access Dashboard relies on ROR.
Key quotations
“But actually, in the end, with all of the architecture and systems we had to change and the move from Microsoft Academic to OpenAlex, the shift to ROR was one of the easiest ones. In fact, we just dropped the entire ROR dataset into an identifier column. It was very simple.”
“And with this broader open data ecosystem, if people feel responsible for contributing to collectively raising the quality of it and working with these community infrastructures, then the capacity for improving the data for everyone, so that everyone’s data looks better, is just huge. And it’s sometimes a challenge, because people are not used to feeling like they have authority. In many cases, data was always something that was done to them. And yet this is data about the stuff we are doing, and the organizations that we are.”
“Without the underlying infrastructure that ROR provides to help us triage data from multiple data sources and connect it to organizations at the right level, we couldn’t do what we do. And as we move forward with what we’re trying to do, and try and scale up and scale out the kind of stuff we’re doing, it’s great to see that ROR is quite frequently a couple of steps ahead. ROR is thinking about the same problems and trying to address them as we can see them coming down the road ahead of us.”
– Professor Cameron Neylon, co-lead of the Curtin Open Knowledge Initiative
Amanda French
Thank you so much for doing this with us. Can you please tell us your name, title, and organization?
Tell us about the Curtin Open Knowledge Initiative. When did that get started and why?
Cameron Neylon
COKI, as we call it, started probably in 2015 or 2016. Lucy and I both returned to Australia after having been in Europe and overseas, and we found the level of conversation about open scholarship in Australia to be quite backwards, and behind, and kind of frustrating. And it was particularly frustrating because it was clear that this wasn’t for a lack of interest or desire to move things forward: it was in large part because the leadership of universities weren’t engaging with these issues, because none of the information resources that they were using brought this up as an issue.
Australia is and has been particularly obsessed with university rankings, partly because the sector is very dependent on international students as a revenue source. But as we know, those rankings are incredibly narrow, backwards looking, conservative, opaque, and actually not very informative. And they certainly don’t do anything to get a university to address questions of open access, data sharing, staff demographic diversity, or many of the kinds of issues that are bound up in this idea of open knowledge or open research.
What we eventually realized was that there’s this gap in knowledge, this gap in understanding, and this gap in information resources. So the idea was to do a better job of providing actionable information in the form that universities are expecting to see it, a form that shows progress towards aspects of open knowledge and comparisons with other institutions, and then that would be one way of provoking change.
We were very lucky to pitch this to a receptive Deputy Vice Chancellor for Research who had just started, and as a result, we got a lot of support from the university to take this forward. That’s all very abstract, of course. What we actually started to build was a collection of open data about institutional practice, about research outputs, open access, citations, traditional kinds of things, but also things like staff demographics and other kinds of information that we thought were relevant to this big picture.
We were very dependent on the growing set of open data resources that were developing, have continued to develop, and will continue to develop. And we got lucky in our timing, I guess, in the sense that we started at a point where those open data resources were just about good enough to compete with proprietary data sources. But they’re accelerating and improving at such a rate that now they are vastly superior, in almost all cases.
That and various advances in cloud infrastructure and computing allowed us to bring all of these datasets together, and so with the goal of making the information actionable, we essentially brought the big open datasets together into a large database using cloud infrastructure. Then we set about building things that we thought might be useful. And as I said, we had the financial support and resources that gave us the luxury to do that and let us do it properly rather than doing small projects. That has let us build up this immense data resource, which is really powerful, but it has also let us build some of the kinds of information resources that we think are needed to help people make intelligent decisions about change.
Amanda French
Amazing. So when and where did you personally first hear about ROR?
Cameron Neylon
That’s kind of hard to pin down. I have been invested for a long time in the idea that persistent identifiers are central to making use of open information at scale, and we’ve learned that over and over again. When we started COKI, it was just before ROR existed, although there were conversations happening about heading in that direction. But Digital Science had made the GRID database available under an open license, so we were happy to be able to use that as a source of information for indexing around institutions. And of course, the GRID IDs were used by Microsoft Academic. And Microsoft Academic was one of our central data sources.
Then, as ROR developed, first as a concept and then as a reality, we were watching that whole journey, waiting for the moment when the maturity of the systems was there to jump across, because we obviously preferred something that was organized through community infrastructures. The thing that really pushed us across in the end, of course, was Microsoft Academic shutting down and OpenAlex stepping into that gap, specifically. That coincided with a range of things we were doing. But actually, in the end, with all of the architecture and systems we had to change and the move from Microsoft Academic to OpenAlex, the shift to ROR was one of the easiest ones. In fact, we just dropped the entire ROR dataset into an identifier column. It was very simple.
Amanda French
That’s great to hear. I’m talking to an increasing number of people who are using that OpenAlex dataset, and thereby using ROR, because ROR is currently the only external institutional identifier that they use.
Cameron Neylon
What’s central in our work is that we bring all these datasets together. We have OpenAlex, ROR, Crossref, Crossref Event Data, Open Citations, OpenAire, PubMed, and I’m probably missing a few. We bring all of these datasets together, and we organize them around community governance and persistent identifiers. And rather than just saying, “Okay, what can OpenAlex tell me about DOIs connected with this institution as identified by ROR?” we can do that across multiple datasets. At the moment, that works most effectively for DOIs, because the DOI has the widest uptake as a standardized identifier across these systems.
But that also points us to what’s really powerful in terms of being able to connect these datasets up. Increasingly, the first step we take with integrating a new dataset is if it doesn’t have those standardized, persistent identifiers in it, we do the mapping across, because the dataset is just not very useful without it. PubMed is a good example of this; I was working with it the other day. It has a bunch of institutional identifiers, but actually mostly the affiliation information in PubMed appears to be in the form of strings. And we just can’t leverage that dataset as well as we might for organizational information, because those links aren’t there. We can leverage it really well in terms of the publications, and increasingly for datasets as well, because we’ve got the DOIs. But for organizational information, it’s just that much weaker, so things like getting all the information for funding decisions is a lot harder than it needs to be.
Are there any other entities that you wish were using ROR IDs more?
Cameron Neylon
Oh, I mean, everyone. It’s really difficult to describe clearly just how much of a difference it makes. And I think that we’re rapidly moving towards a world where this is going to become self-evident. In the old days, if you wanted to ask a question, you first started with, “Okay, which dataset should I use to answer this question, and what limitations does that dataset impose on me?” With open data and cloud infrastructures and the availability of these datasets as a whole, that’s not where we start to answer a question. We ask, “Which datasets can we bring together to maximize the amount of information and the precision that we can apply to addressing this particular question or problem?” The datasets that are easy to integrate are the ones that we use. Increasingly, if there isn’t a ROR ID or the ORCIDs aren’t properly handled, then we just don’t use the datasets.
The other side of that is because we are operating at a fairly large scale and making these public information products, we get a lot of people coming back and saying, “Oh, you’re missing this,” or “That’s not there,” or “There’s something wrong here.” We can feed that back, and we can feed it back really easily. An example of this exactly with ROR: there was a university and the librarians noticed on the global open access website that the counts of outputs seemed a bit down. They looked closely at name variants, and they discovered that there was a bookstore on campus, and OpenAlex had assigned a bunch of the outputs from that university to the bookstore. OpenAlex is still a work in progress, so that kind of thing does happen. And the bookstore wasn’t listed in the hierarchy for the institution; if that had been the case, everything would have flowed up nicely.
What that story illustrates is that we don’t find these errors. The people working with the data at scale, making information products, we don’t often find those kinds of errors. They’re always found by people on the ground who know the context and know exactly what the numbers should look like. We get a couple of emails a week from various people saying “This is wrong,” “This is under-counting,” “This is over-counting,” “These two organizations don’t belong together,” or “These two organizations do belong together.” And it’s really easy for us to pass that information back up when there are good identifiers. And we can say, “No, this DOI should link to this ROR,” or “This ROR should probably be a child of that ROR.”
That flow of curation information into the system, combined with the ease of use when things are easy to interconnect, I think is ultimately going to make these little, isolated, increasingly fragmentary datasets that are difficult to work with because they don’t have the coverage and they don’t have the interconnection less relevant in the long term.
Amanda French
Fascinating. Well, I hope you and your staff do refer those kinds of issues to ROR, because we are always happy to make those kinds of corrections. If there is a bookstore that should or should not be in the relationships of a ROR record, we’re happy to add that or take it out.
Cameron Neylon
It raises lots of really important questions about the importance of community governance. In these cases, a lot of the time, when someone tells us something’s wrong, sometimes that’s a mistake we’ve made, and we can correct that. Sometimes it’s a mistake in someone else’s data system, and then we can pass that on and explain it to them. And sometimes it’s a thing where there’s reasonable grounds for disagreement.
And in fact, what we said in this case was, “It’s not our place to say whether that bookstore is part of that university. That’s a decision you guys have to make, and here’s the ROR request form for when you figure that out.” And I think that’s a really important part of the whole story of changing the way people think about corrections.
In the space of bibliometrics and scientometrics, almost every university in the world has people whose job it is to correct the things that are wrong in Web of Science and Scopus. This is like an extra full-time person on top of the hundreds of thousands of dollars that are spent on a subscription to these products, working to help correct them. But that data just goes into a black hole, which we can’t reuse.
And with this broader open data ecosystem, if people feel responsible for contributing to collectively raising the quality of it and working with these community infrastructures, then the capacity for improving the data for everyone, so that everyone’s data looks better, is just huge. And it’s sometimes a challenge, because people are not used to feeling like they have authority. In many cases, data was always something that was done to them. And yet this is data about the stuff we are doing, and the organizations that we are. I think it’s a really interesting transition to try and navigate, to get everyone get more engaged in feeling like they have a stake in making these things better.
Amanda French
It is interesting too, because ROR’s curation model, as I’m sure you know, is not the same as something like Wikipedia or Wikidata, in the sense that we curate everything. Anyone can request anything, but we evaluate that and approve or decline it centrally. Wikidata and Wikipedia have a decentralized, distributed editing model, whereas we have quite a centralized curation model.
But we also don’t have a model in which only certain people can make requests, or where there is a particular person at every organization who is responsible for making sure that their information is correct in ROR. We will take a request from anybody; you don’t have to be affiliated with that organization. And we evaluate that in the open based on openly available information and on what makes sense for ROR.
And I think that model is unusual for people to understand. I think they tend to have a kind of a binary notion of authority over data. Either there’s a centralized authority who is making decisions, and you are lucky if you have any input into that, or it’s something that’s entirely distributed. I really like our model, because I do think it has the best of both worlds. We will entertain any corrections that you wish to give us, but we do also review and curate that quite carefully.
Cameron Neylon
I think I would agree, in the sense that there’s clearly a tension here, right, between consistency of application and the scale at which the work can be done. With federated models, people assume that what you might lose in precision you gain by having this massive scale of work that can be done. But what you also do is create a massive scale of work that needs correction. It works, kind of, in some parts of Wikipedia or Wikidata, but mainly because of the absolutely vast scale of those enterprises. And anyone who’s done anything on crowdsourcing knows that it’s really, really hard to replicate that level of success at a smaller scale, so the tension there of needing to have a reasonable amount of effort and a reasonable application of resources but still get something out that’s usable drives you toward the other end of that spectrum, toward centralization.
And indeed, I think that’s again where the community governance and the model of transparency comes in. And it’s got to be flexible, not rigid, because the other assumption people make is, “Well, surely you can automate this or have some sort of system that just does all the checking for you.” AI, wave hands, wave hands. And actually, none of those things work, in part because there are bad actors in the system, and you’ve got to be on the lookout for that.
That’s particularly true in terms of organizations and who they are and what they’re connected with and who’s connected with them. Those are exactly the areas where we’ve suffered a lot of fraud in the scholarly system, so that’s got to be managed in some way that’s ideally flexible and transparent, but also trustworthy. At the end of the day, that’s where you’ve got to be going, otherwise these things just aren’t usable.
Amanda French
Can I ask, do you teach?
Cameron Neylon
I don’t do a whole lot of teaching. My role is mainly research, at least at the moment. Our work doesn’t neatly fit into a teaching program in the school that we’re within. Like a lot of multidisciplinary groups, there are challenges in terms of where we are and what we’re teaching. It’s a peculiarity of the Australian system that there is a tendency to separate research and teaching, and that’s driven by the financial model that the government imposes on Australian universities more than anything else. So, yes, I think there’s always some challenges around that.
That said, we are in the school that contains the Information and Library Science program, and so we do teach into that, and then more broadly, into what you might call Critical Information Studies. If you’re over in the sciences, you’d probably call it Data Science and have a little bit of ethics and critical theory applied. If you imagine the other side of that, we’re starting from critical perspectives about what information is and what information does and whose benefit it serves, and then teaching a bit of the technical side so that people get an understanding of how that works out in practice: what the nitty-gritty of actually doing data analysis and visualization looks like, and why the tools are not neutral, and why it often looks like the entire world’s data has been shoved through an Excel spreadsheet, because the limitations of Excel spreadsheets are what drive the things people do with data.
Amanda French
Ha! Right. The reason I asked is, I imagine you have fellows or postdocs or graduate students or whatnot working with you on your projects, and I’m just curious how you address persistent identifiers when you’re passing knowledge along to the next generation, whether that’s in a classroom setting or in an apprenticeship-slash-lab setting.
Cameron Neylon
That’s a good question. I would start by observing that we’ve probably still got some work to do with the current and indeed past generations on the use of persistent identifiers.
Where we do teach it is we have a team, we bring people into that team, and where we educate people about this is through the practice. We have processes by which we write up documents and put them by default on Zenodo in a COKI Zenodo community so they get a DOI and so they can be automatically connected to people’s ORCIDs. We use the Tenzing tool to apply CRediT taxonomy when we prepare things, or at least we try to do that as much as possible.
At the social level, then, if you like, we try and embed it as much as possible into what we do and how we do it. And then at the technical level – and most of our team is pretty technical – it also goes into the sort of architectural principles we have for our data structures. In more traditional teaching, we teach some courses around data and telling stories with data.
And actually, introducing the concept of persistent identifiers and why they matter is always a challenge. Do you present it in kind of an abstract and theoretical sense of how well the system could work? That doesn’t really speak to very many people. Or do you present it in a much more practical and concrete way? There, you run up against the fact that at least until recently many of these systems just didn’t work as well as they might.
I’m always reminded of the person who, when being asked to sort out their ORCID record, upon being told this was the last time they’d need to sort out a personal profile as a researcher, observed “Well, that was what I was told the last five times I had to do a personal profile as a researcher, and every one of those has fallen by the wayside, and now you want me to do another one, so how can you promise me another one’s not going to come along next week?” One of the big challenges with all of these systems is they will work really well when everyone’s using them and when everyone doesn’t even think about using them, but getting there is hard work.
Amanda French
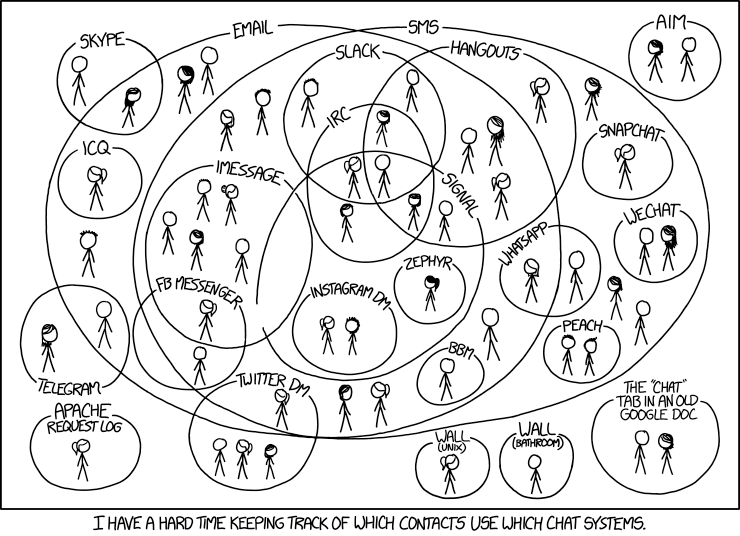
Yes. And the metaphor I always think of, which is possibly a bit too simplistic, is the telephone. You have telephone numbers, and everyone needs a unique telephone number, and telephones themselves increase in utility the more people have them. And the more people who have telephones, the more important it is that you have unique telephone numbers. And if I were in a research position at a university, I would probably start doing all kinds of research into party lines and alphanumeric exchanges and the emergence of cell phones and things like that, you know, looking at the history of how we got to the globally standardized system that we have today for telephone numbers.
Page 44 of the Portland, Indiana telephone directory from 1920, available via DPLA on Wikimedia Commons
Cameron Neylon
And I guess the challenge with that, thinking about this, is that if you take that analogy through to the current world of social media or streaming video platforms, everything’s so vertically integrated that I don’t know if very many people are aware of why it is that a phone number can be a standard thing, despite the fact that lots of different people make phones and lots of different carriers will carry phone calls. And similarly with email, because those things are the last residue of that in the world as a whole.
Most of the things we deal with don’t have those standards, and that’s why they’re awful, right? It’s why you’ve got three streaming subscriptions, not one TV aerial, and why you’ve got seventeen different direct message or personal messenger accounts across multiple different services, none of which you really like to use, but because there’s one person who does like to use that particular one you have to have it. And you know, the seemingly obvious concept that you should be able to get those messages wherever you want to, and send them to anyone based on a standardized sort of protocol or system, has partly been lost. And that’s part of the battle of making the case for how these things can work better, is, yes, recalling the fact that you can in fact make phone calls and you don’t have to have an AT&T phone and a British Telecom phone.
That’s right. I think that’s such a good point about looking at the failures of standardization, and the takeover of non-open commercial services for these things. I suppose some other examples would be power systems, globally. You know, when you travel from country to country, the plugs are different in the United States than they are in Europe, and, as I discovered recently, also different in South Africa. Measurement systems, metric versus non-metric, not standard everywhere you go. Even driving: which side of the road you drive on and which side of the car the steering wheel is on. All of those things are small frictions, and yet they’ve been standardized enough to where they work regionally, and we can see how well it would work if they were standardized globally.
Time zones, actually! Obviously we have to have time zones, just because of the fact of having a globe, but I keep thinking, “Wouldn’t it be nice if everybody got rid of Daylight Saving so that we didn’t have the problem of wondering if such and such a country has gone on Daylight Saving?” If it were a standard interval between each timezone and didn’t change with the seasons it would make scheduling international meetings so much easier.
Cameron Neylon
And also the weird time zones, as well. The power one is actually quite an interesting one, because there does seem to be an emerging plug standard. There are actually moves towards persuading everyone to just use one. I mean, it’s a bit ridiculous, but given that a lot of devices that we use, with some exceptions, can run off 5 volts, an awful lot of things could just use USB plugs. There’s a 5 volt / 12 volt / 24 volt issue, but a lot of things could use USB, and we’re sort of iterating towards that. Interestingly, it’s driven not really by thoughtful top-down standardization, but by frustration of people who are traveling and the bag full of adapters that you’re carrying, if you’re going to more than one place. I do actually carry around now just one or two USB adapters with swappable plugs, because that works reasonably well. Until I get to South Africa and realize that that particular plug is quite unusual.
But yes, I think there’s something really interesting there. The other example from the power world, of course, is that once upon a time you couldn’t take any appliance from, say, the US at 110 volts and bring it to anywhere in the world running at 240 volts. But these days, I don’t even remember that I should probably check before I plug something in with an adapter, because the transformers are all standardized to deal with both cases, so you don’t usually have to think about needing a step down transformer to operate.
Conrad H. McGregor, Map of the Countries of the World Colored by the Nominal Voltage and Frequency They Use, available on Wikimedia Commons
And that gets back to things like ROR as interchanges, where yes, there are legacy systems of other identifier systems out there, and there are systems that perhaps ROR shouldn’t cover that maybe ISNI needs to, but at least if we’ve got places to do lookups, and those are, again, centrally maintained and kept reasonably up to date, then we don’t need to think too much about that as we translate between things.
What I wish we also had, and ROR does this well, and other identifier systems not as well yet, is exactly this thing of collections of objects. Most of the work we do involves taking sets of research outputs and bundling them up into groups where those groups might be, they might be the outputs of a person, they might be the outputs of a project or an institution or a country or a discipline, or whatever it might be. And in the institution case, where because of the parent-child relationships in the ROR schema, we can go up and down those hierarchies and figure out the level we want to operate at. Whereas I’d say with DOIs, that’s not so easy, because there’s a lot of complexity and inconsistency in relationships between DOIs for collections versus DOIs for objects. And that’s before I start getting annoyed about ISBNs and book chapters.
Project IDs, I think, are an area that’s missing a lot of space, and I think institutions really ought to do a much better job of providing ways of interconnecting between ORCIDs and institutions. There’s lots of opportunities there. And thinking carefully about those collections kind of questions, I think, is really valuable.
Amanda French
Maybe that’s a good occasion for me to ask, what do you hope ROR does better in the future? What can we do that would make your life easier?
Cameron Neylon
There’s very little that we bump up against as a problem. At the moment, I think most of the immediate issues we’re facing are to do with the challenges of actually making the interconnections, so the assignments of, say, outputs to two organizations, and the heuristics involved with that, which is a hard problem to solve.
The area where I can imagine the real benefits will arise, and this is already happening, is the expansion of the set of organizations being covered, and that’s really welcome. When there’s a new release, that number clicks up and you think, “Oh, my brain is about three releases behind, I thought it was still 95,000, and now it’s 110, 115, 120, something like that.” [Note: It’s currently over 107,000.] I think that’s great. I’m really glad that people are thinking hard about how to manage those questions of curation, not because I have opinions necessarily about how they should be done better, but because I know that they are really hard problems. I’m glad smart people are thinking about them.
One of the questions I have, and it’s an issue that, again, is a real challenge, both from a curation perspective and from a schema perspective, is how we can tackle the question of units within organizations and what that looks like. I’ve seen that on both sides. I completely understand why people would want to run screaming in the opposite direction from even trying to deal with it. And I can also see from within institutions how important it is to have the capacity to be able to do that. I think that’s an area that’s really worth thinking through. And the answer might be something like component DOIs, so actually for ROR to not deal with it, but to allow institutions to self-manage. I can also see that going horribly wrong.
Amanda French
Right.
Cameron Neylon
I’m not sure I’ve got a better solution. But one of the things we see really frequently is exactly that question of how to reflect back to an institution what the parts of it are looking like while having to deal with the fact that only the institution itself has any sort of real knowledge of what that looks like. And it’s changing so fast!
Amanda French
Yes, I know. Departments, in particular, will merge and change names and whatnot. And I have to tell you, I absolutely believe that there would be internal arguments at an institution about what their institutional hierarchy would be.
Cameron Neylon
These are real issues, right? This is the thing we discovered, I mean, coming right back to the starting point of why we were doing this in the way we did. What a Vice-Chancellor or the University President sees is something like “Here are the faculties, here are the number of outputs, here are the number the citations, here’s the amount of research income.” It’s really at a very high level. And those numbers are garbage for the most part. They are appallingly bad. Years out of date, and often related to an organizational structure that hasn’t existed for half a decade or more.
And so there’s a desperate need for automating more of this so that information will be more up-to-date and more responsive and more flexible. But at the same time, if heads of schools are being judged on how much research revenue they’re getting assigned to them, and they’re being judged on how much they’re collaborating across the university, are they going to quietly not argue about where that money got assigned to, even if it then got spread out across multiple faculties or departments?
It’s a real issue on which people’s livelihoods depend. They’re really complicated questions, and getting them wrong can break institutions. Information has to be summarized, and summarization is a lossy process, and so you’ve got to make decisions about what you lose and what matters.
And maybe that’s the other piece, and I think this isn’t just a challenge for ROR, but the question of literacy. How do we raise the literacy of all the players? Not to the extent that they need to know the nitty-gritty of all the details of how everything works, but so they can ask intelligent questions about how the information that they’re getting has been processed, and whether at least in principle there’s a transparent audit trail so they can go back and check and see how things might have looked if it was done differently. And again, that’s something we build into pretty much everything we do now.
It’s amazingly common in the proprietary world not to do this. University rankings are particularly bad at this. The thing you do if you’re going to change something is you do one run the old way, and then you do your next run the new way, and you look at how different they are. And you make that clear and transparent, and ideally, you’ve got open source code. It’s critically important, but it’s amazing how rarely it’s done, and even where it is done, without community-owned open indexes and infrastructures and systems, it’s really hard for that to be for that to be transparent.
These are the real challenges. People are exercised about artificial intelligence, and this, that, and the other, but the problems aren’t really to do with the scale at which these computational systems can work. They’re to do with the fact that people are making decisions so far away from the point where the context and on-the-ground information is that the quality of the information that’s going through those systems needs to be a lot higher than it is.
And the consequences of getting it wrong is that entire departments or even entire universities get closed down. Whole programs of research cease to exist. Teaching programs that you might need tomorrow are axed, because apparently someone didn’t get a job five years ago. Every time there’s a major world event, there’s a story that goes round about how someone three days earlier didn’t get a grant about that particular thing, because it wasn’t important. And suddenly it is.
Amanda French
Yes, absolutely. Well, we can wrap up. What else would you like to say about ROR or about your work?
Cameron Neylon
At core what I would say is we couldn’t do what we do without ROR. We’re focused on organizations and institutions. Without the underlying infrastructure that ROR provides to help us triage data from multiple data sources and connect it to organizations at the right level, we couldn’t do what we do. And as we move forward with what we’re trying to do, and try and scale up and scale out the kind of stuff we’re doing, it’s great to see that ROR is quite frequently a couple of steps ahead. ROR is thinking about the same problems and trying to address them as we can see them coming down the road ahead of us. So, yes: keep on keeping on.
Amanda French
We will! We’re feeling good. We are hiring more curator help and thinking about ways to scale up that curation that you noticed is so crucial. This has been really marvelous. I only wish we could talk for another half an hour about infrastructure generally. Thanks so much.
Cameron Neylon
Have a good day.
Questions? Want to be featured in a ROR case study? Contact community@ror.org.



.jpg){kind=link}

{kind=link}